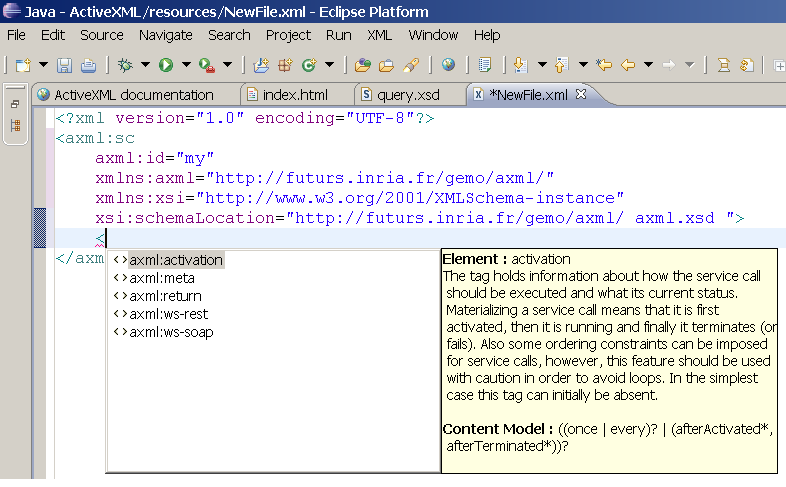
ActiveXML documentation [under development]
Introduction
This document is a report on the development of ActiveXML software. It is supposed to be
useful for both: end users and developers.
ActiveXML is based on XML and Web services. An active document
is an XML document with embedded service calls to Web services, which enrich the document upon activation.
This technology in a peer-to-peer setting relies on the fact that peers communicate solely by means of Web services.
The ActiveXML language has a predefined set of Web services for every peer, which enables distributed data management. Still, any peer can also provide other services,
which actually causes the network to become a distributed database.
We can distinguish among several kinds of service calls:
- Service calls to the Web services that are known to be in the peer-to-peer network. These Web services
consist the interface of a specific peer, and information about it can be
meaningfully used, for example, by optimizers. An example of such a service is a QUERY service
- Service calls to unknown Web services. These can be any Web services on the Web. Though a service call
behaves similarly (i.e. it enriches the active document) the information about
the Web service is usually unavailable and cannot be used by the distributed system. For example, it is not trivial
to optimize a call to some Amazon.com service
- Continuous service calls. These are the calls to Web services that know how to stream back data, and notify about the
end-of-stream. Basically, it is a matter of the communication protocol between a service call and the Web service.
For instance, current implementation ships information about a service call (with the endpoint where to reply)
to the Web service as a SOAP header
- Simple service calls. These are the calls to one-shot Web services. Such Web services do not stream
back the data asynchronously, but rather return it directly (if there is any) within the response message
Calling a Web service in any way is not a problem these days. There are libraries that allow to call a Web service
synchronously, asynchronously, one-way or two-way. However, the promise of ActiveXML is to
be able to call Web services declaratively. For instance, instead of creating software for
calling some SOAP Web service, one could simply create an active document with a service call to that Web service
and pass it to the engine to evaluate. Moreover, instead of creating software for piping Web services one could create
an active document where one service call has another service call as a parameter.
This shows that the correct usage of ActiveXML
lies in creating, transforming, sending, receiving active documents and materializing service calls inside them.
In the following sections the current architecture of ActiveXML will be presented. The details
about installation and usage will be provided. The developers will be given a more indepth information about the specific
implementation points and organization of the code in the repository.
Back to top
Architecture
In this section a high level architecture of ActiveXML is presented.
Organization of Components
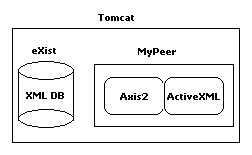 |
There are 4 software components that make up an ActiveXML peer:
- Web server. We use Tomcat 5.5
- XML database. Currently we use eXist
- Axis2 Web service engine
- ActiveXML service calls execution engine
Axis2 and ActiveXML make up a Web application
that is deployed in the Tomcat 5.5 Web server. Then the Web application is configured
to connect to eXist database where each peer has its own repository of documents
(a separate collection).
|
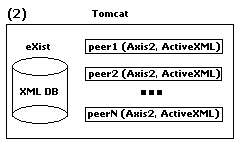
Actually the components can be organized in several ways. In the simplest (and most expensive) case everything is in
the Web container (Tomcat) as Web applications. Hence the peer has its own Web server and its own database instance.
It is, nevertheless, possible that several peers share one Web server and the same database instance. Possible configurations
are depicted bellow (see how to create new peers). As the picture shows there
can be several peers residing in one Web server while
the database can be inside or outside the Web server. The peer-to-peer network is a network of such possible configurations where,
as already mentioned, the peers communicate only by the means of Web services.

Deeper Look into a Peer
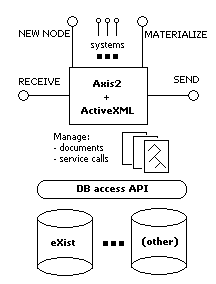
First of all, one can use arbitrary XML database for peer's repository. However, there is still no standard way for
accessing XML databases, querying or updating them. Relational databases have JDBC, which is a standard way to
connect to SQL data sources and post queries. XQJ, the analog of JDBC for XML datasources, is on the road, as well as
standard for XML updates.
Taking such situation into account the decision to create our own API is reasonable. Therefore above XML database there is
a DB access API layer (see the picture). This API can be seen as a very modest XQJ with updates using XUpdate. We currently
have an implementation of this API for eXist, other databases will need their own
implementations (drivers). It is important that other databases support XUpdate since the core ActiveXML services
are using this language for updating active documents. Worth mentioning that it is relatively easy to write a driver
for XML databases that support XML:DB interface, like eXist does.
Above the DB access API is the document management layer. A peer has
a bunch of documents in its repository. Those documents may have service calls inside them. This roughly describes what
constitutes the model part of the software (in MVC architecture). The controller, on the other hand, is a piece of software
that manages the model. It sits in between the repository and ActiveXML clients (seet the picture)
and updates the state of the model. For instance, document management layer is responsible for marking service
calls as active/terminated, also for executing a scheduled service call, etc. In previous version of
ActiveXML this layer also kept all the repository in memory as DOM objects. Now it only keeps
references to the interesting parts of active documents using XPath and XQuery.
A peer is visible to the outside world only by the exposed interface, i.e. the Web services. This can be treated as the view
part in MVC architecture. So when someone pushes a button (invokes peer's Web service), the state of the peer changes,
and the model (some document) is updated by the controller.
Web services in ActiveXML are facilitated by Axis2. Its beautiful
design allows plugging-in new Web services quite easily. This is essential as the functionality of a peers is exposed only
by Web services. For instance, if peer is able to answer a query over streams it exposes this functionality as a
Web service (let's call it GenericQueryService), so that other peers could call this Web service from within
an active document. There are several Web services that are inherent from ActiveXML
(shown as buttons in the picture):
- Three algebra Web services, that enable distributed data management:
- ReceiveOperator [shown as RECEIVE], through this Web service results come to a service call. Roughly speaking,
when a Web service is invoked from within an active document, the response is redirected to this Web service. It is
responsible for preparing the incoming result to be correctly merged into the document. For example, it assigns
the timestamp and origin attributes, ensures that the ids of incoming and existing service calls don't overlap, etc.
- SendOperator [shown as SEND], this Web service is sending data to an address specified. More specifically,
it calls the respective ReceiveOperator and passes data to it. Normally this Web
service is not used, as the ReceiveOperator can be called directly, therefore any Web
service that would call RECEIVE can be titled as SEND. Although SendOperator usually is not invoked,
service calls to this Web service are indispensable since they bare special
semantics
- NewNodeOperator [shown as NEW NODE], this is a utility
Web service that allows to install (active) data
in some peer's repository. It can install new document or append data as children for a specific identifiable node.
The semantics of this Web service impose that the newly installed node is evaluated
- MaterializationService [shown as MATERIALIZE] has the following operations:
- evaluate, will materialize the document in a depth first manner. This means that
when a service call has other service calls as parameters, the parameters will be materialized earlier. The ordering
of execution can be explicitly overridden, which makes the active document look like a graph
- evaluateNode, behaves much like evaluate but materializes the
document starting at a specified node
- activate, will activate a specified service call and will follow all the explicitly
defined constraints. This operation will not follow a default (depth first) execution order
The above listed basic interface can be extended and is still under discussion. For example, do we need a Web service
like InstallDocument, or should we add an input parameter
to NewNodeOperator that would install a document without evaluating it; do we need
an evaluateData operation for MaterializationService that would
accept as input active document and evaluate it?
All the other Web services are extensions of peer's functionality and can simply be considered as plug-ins. Beside the core ones
currently there are following services available:
- GenericQueryService, this Web service is a relatively simple implementation
of stream processing engine. As an input it gets a query declaration and parameter streams.
It can also be used to answer XQuery
queries over the database
- DummyStreamService is useful for testing. When called it streams back result of
a specified query
- OptimaxService, distributed query optimizer. Given an active document the
Web service transforms it into a distributed plan. The documents that have service calls to
GenericQueryService are candidates for optimization with this Web service
For more details on peer's Web services find examples and schemas presented later.
What is a Stream?
Now some clarification about streams. A stream is
a channel of data between a service call and the Web service it is calling. The important thing is that data keeps arriving
to the service call continuously (and asynchronously) until the end of stream. The procedure is as follows (see the picture):
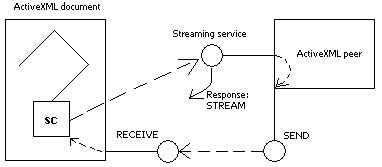
|
- A request comes to materialize some service call
- The service call invokes the Web service and together with the message attaches
a header with information about itself
- The Web service repsonds with a message marked as STREAM (if it has what to stream and if it recognizes the header)
- The service call stays active if the Web service response was marked as STREAM
- Then it depends on the Web service when it sends data to the requesting service call.
|
In the picture above SEND is shown as a separate service, still, the streaming service can directly call RECEIVE. It is then
said as behaving like SEND. So to put it simple, a stream is a channel between SEND and RECEIVE. A streaming service is responsible
for SEND whereas a service call is the RECEIVE'er.
Worth noticing that a stream can be seen as a communication protocol, nothing else. Current implementation works as
described (using markers), however,
other implementations or extensions are apropriate. For example, it looks natural to use WS-Addressing for addressing the service call.
Also a mechanism of handling sessions can be fruitfully utilized, because a service call is simply a client for a specific
Web service.
Actually the concept of streams also captures non-streaming communication between service calls and Web services. In this
case the stream consists of one item that is sent directly as a response to the service call and is implicitly marked with
END_OF_STREAM. Therefore, materializing a service call ends up in 1) service call termination if the Web service responds with
the END_OF_STREAM (it is implicitly assumed), or 2) it stays active if the Web service responds with the STREAM marker
and terminates only when its RECEIVE detects the END_OF_STREAM.
A General Picture
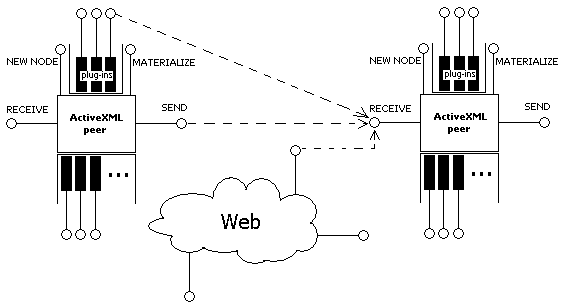
To put things together what we have is the architecture shown in the picture. First, there is a peer-to-peer network
of ActiveXML peers. The peers are extensible by plugged-in Web services. Note that Web services
are only the interface to the underlying software, which can vary from a very complex system to a simple function. Although
the plug-in architecture of a peer resembles much an ESB (Enterprise Service Bus) its purpose is
quite different from just orchestrating Web services.
In particular, the plugged-in systems are supposed to make use of ActiveXML.
This means that the exposed Web services:
- can stream data. For instance, it can send a message on some event ("alerter")
- can try to materialize some service calls before responding to produce more results ("lazy")
- can transform the requested query into an optimized one in order
to bring results from the whole peer-to-peer network quicker ("optimax")
- can evaluate an active document in a special way
- can serve as an integrator of results from several Web services, i.e. by specifying several service
calls inside an active document and doing a query over it
- etc.
In essence using ActiveXML means 1) using special syntax to declaratively specify calls to Web
services and 2) using the engine for materializing those service calls. Hence ideally service consumers
would write active documents
and materialize service calls inside them. While service providers would develop systems and expose
them as Web services potentially internally also using ActiveXML.
Besides the peer-to-peer network, XML and Web services allow ActiveXML to enter the Web in general.
As it is shown in the picture RECEIVE can get data from everywhere, that is, an active document can contain service calls to
any Web service, be it on another peer or somewhere on the Web. Similarly it is not forbidden for external systems to call
Web services inside the peer-to-peer network if it makes sense
to them (because the returned data may be active). Moreover, since streaming is just a communication protocol
nothing stops Web services outside the peer-to-peer network to stream data back to a requesting service call through
its RECEIVE.
User Guide
In this section you will find information about configuration, creation of active documents and
materialization of service calls. It will be shown what is visible to the user and what is happening behind
the scenes.
Installation and Configuration
It is quite easy to start using ActiveXML when you know about what it is made of. The
distribution is created in such a way that it includes everything that is needed for the start
(except Java Runtime Environment), namely the 4 components: Tomcat,
eXist, Axis2 and
ActiveXML (see the compenents representation).
First thing to know is that the distribution is simply the Tomcat Web server with several
Web applications included, specifically: eXist and MyPeer. The latter
is actually integrated into Axis2 Web application in order to make use of the Web service
repository management.
|
From the file structure you can easily see what was changed in Tomcat:
- the root folder was renamed into 'ActiveXML'
- unneeded Web applications under webapps/ were removed, added 'exist' and 'MyPeer'
- some libraries were put to the shared classpath under shared/. The most important ones are
Axis2 libraries and database libraries
The following configuration changes were performed for Tomcat:
- in conf/catalina.properties paths to new shared folders were added (shared/db/*.jar, shared/axis2/*.jar)
- in conf/server.xml ports were changed into 6969 (for HTTP requests) and 6960 (for Web server shutdown request)
So generally not much changed in Tomcat, therefore for things like changing a port, starting,
stopping or anyhow configuring the Web server please follow Tomcat's
documentation.
Perhaps it is also appropriate consider another Web container instead of Tomcat, for instance,
Jetty to make the distribution smaller.
|
Running
Only 3 things are needed to know:
- JAVA_HOME environment variable must be set. It must point to the JDK or JRE root directory.
JRE_HOME variable name is also fine (e.g. JRE_HOME=C:\Program Files\Java\jre1.5.0_09).
Usually for this purpose one can use set command line tool.
This point implies that you have a JVM on your computer.
- use bin/startup.bat or bin/startup.sh to start the Web server
- use bin/shutdown.bat or bin/shutdown.sh to stop the Web server
That's it. 'ActiveXML' folder can be coppied to any writable media like the hard disc or a USB key
and you can consider to have ActiveXML installed.
NOTE: on Linux be sure to make bin/*.sh files executable
NOTE: if you have another instance of Tomcat running on your machine, you will need additional
steps, for example, setting the CATALINA_BASE variable.
Web Application: eXist [ ActiveXML/webapps/exist ]
In the full distribution eXist is included as downloaded
(*.war=~23M, unzipped ~50M). Hence using an external database instance could considerably reduce
the weight of the distribution and not only in size. For instance, think that you would want to cary
the ActiveXML peer on a PDA or a USB key. Therefore one should consider the
(3) type of component organization.
You can browse eXist database at
http://localhost:6969/exist/admin/admin.xql (login: admin/exist). Alternatively
you can try the Java interface at http://demo.exist-db.org/webstart/exist.jnlp which
is, however, not always working.
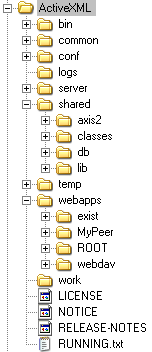
Web Application: MyPeer [ ActiveXML/webapps/MyPeer ]
As it was mentioned ActiveXML is merged with Axis2
Web application. This choice is made in order to utilize the internals of Axis2
when dealing with Web services, which is crucial for ActiveXML. For deeper
information please read Axis2 documentation.
For now there are 4 important things to know about Axis2 in
ActiveXML distribution:
- MyPeer is an extension of axis2.war
- it has a Web services repository by default configured under WEB-INF/
- conf/axis2.xml, the repository configuration file. Here one can specify in/out phases in order to engage modules
for a message flow, also one can configure transports, ports and everything else related to Web service mechanics
- modules/*.mar, a module is a collection of handlers that are used to process an incoming/outgoing message. The modules are pluggable
and engageable during a specified phase of a message flow. *.mar (module archive) is simply a zipped collection of resources,
like classfiles, libraries and module.xml. There are 2 tiny modules that belong to ActiveXML:
- ServiceCallWrapper.mar, responsible for creating a valid message for the Web service refered in the service
call. For instance, a user does not write a SOAP messages, it is left to this module. It also attaches information
about the service call in headers
- ActiveXMLServiceEntry.mar, makes the ActiveXML context available for Web services.
Without it the engine nor repository would not be easily accessible
- services/*.aar, *.aar (axis archive) is a zipped collection of resources that consist a Web service. It can also be kept unzipped
(the same holds for modules) like it is in case of services/OptimaxService/. So a Web service is indeed an independent piece of software,
that has its own implementation, libraries and configuration, which enables pluggable architecture of ActiveXML
- it has a user interface for managing Web services under axis2-web/;
normally it will be accessible at
http://localhost:6969/MyPeer/axis2-web (login: admin/axis2). Consult it for
service endpoint, WSDL, XSD and other information about web services of the peer
- all the Axis2 related libraries (from WEB-INF/lib/)
are shared
The important files related only to ActiveXML are:
- WEB-INF/lib/axml.jar, this is the engine
- WEB-INF/web.xml, this is the standard Web application configuration file, it mostly has specification for servlets
(both Axis2 and ActiveXML)
- WEB-INF/classes/log4j.xml is the configuration of the logging system. The logs can be found under
ActiveXML/logs/ together with standard Tomcat logs
- META-INF/context.xml contains context specific configuration. Currently it only has the connection specification
to the XML database. This connection is then accessed using JNDI (the procedure is kept to be very similar to connecting to SQL data sources).
Note that other Web containers do not necessarilly have this file, so the JNDI resource must be specified elsewhere
- index.jsp, axml-web/ contains the GUI for the user that wants to evaluate a document, browse the database, etc.
However, it is very modest. This is due to the fact that it is still not clear what the user
interface should look like. It is clear that one thing is the administration tools, still there also should be user
tools. One of possible solutions could resemble the one proposed for Web mashups.
- docs/ contains this documentation with some additional resources
- examples/ have a collection of example active documents that are a good start to
playing with the peer
- xsd/*.xsd are the XML Schema files that declare the types
known to ActiveXML engine. For instance, axml.xsd declares
the grammar for service calls. The schemas can be used for validating active documents. JAXB is used for doing
marshalling from XML to Java and vice versa
As one could guess to open a simple user interface of MyPeer the following
path should be used: http://localhost:6969/MyPeer (after starting the Web server, of course).
context.xml, pay attention when using another Web container
logs
Shared Libraries [ ActiveXML/shared ]
Beside MyPeer there can be more peers configured to live in the same Web container
(and possibly using the same database instance). Therefore it makes sense to share the heaviest libraries among all of them.
- ActiveXML/shared/axis2/, ActiveXML/shared/classes/ contain everything that initially could be found under
axis2.war/WEB-INF/lib/ and axis2.war/WEB-INF/classes/ (~17M when unzipped)
- ActiveXML/shared/db/ contains libraries that enable uniform access to an XML database, i.e.: database access API and
the implementations for a certain providers
- ActiveXML/shared/lib/ keeps anything related but not compulsary to ActiveXML engine.
For instance, it can contain libraries related to GUI or for some Web services
Creating a New Peer
A peer consists of a collection of (active) documents and a set of Web services. In the installation and configuration
section it was shown, how the pieces are put together to have MyPeer up and running. If one wants to add more peers to
his/her Web container the procedure is rather easy (can even be automatized):
- make sure the Web server is stopped (use ActiveXML/bin/shutdown.*)
- copy MyPeer inside ActiveXML/webapps with a
given name (e.g. AnotherPeer)
- change the following resources:
- ActiveXML/MyPeer/META-INF/context.xml, it was mentioned that here connection to the database is configured. In case of
eXist it looks as follows:
<Context>
<Resource name="axml/repository"
factory="fr.inria.gemo.axml.db.DataSourceFactory"
type="fr.inria.gemo.axml.db.IDataSource"
driverClassName="fr.inria.gemo.axml.db.exist.DataSourceImpl"
url="xmldb:exist://localhost:6969/exist/xmlrpc/db/MyPeer"
userName="admin" password="" />
</Context>
It is enough to change the url of peer's repository into: url="xmldb:exist://localhost:6969/exist/xmlrpc/db/AnotherPeer".
What actually happens is that MyPeer and AnotherPeer will have their own
document repositories (collections) on the same instance of eXist (see the picture)
- ActiveXML/MyPeer/WEB-INF/classes/log4j.xml, replace all occurances of 'MyPeer' into 'AnotherPeer' in order
to get separate log files for AnotherPeer
- ActiveXML/MyPeer/WEB-INF/web.xml, replace
<display-name>MyPeer</display-name> into <display-name>AnotherPeer</display-name>
because currently it is the only peer identification method. Usually in a peer-to-peer environment peers have unique ids.
Although it is not implemented, normally a peer should obtain an id when it first joins the network. This is crucial for catalogging
available Web services in the network
- start the Web server (use ActiveXML/bin/startup.*). Now AnotherPeer should be
accessible at http://localhost:6969/AnotherPeer
What is important to understand that after creation of AnotherPeer it lives totally in its own context: it has its
own repository of documents, and its own repository of Web services.
Service Calls and Active Documents
ActiveXML documents (or simply active documents) are XML documents with embedded service calls. Embedding a service call is
just a matter of following the syntax developed for service calls so that the ActiveXML documents engine
would be able to recognize them and apply semantics. Without an engine active documents are normal XML documents. The syntax for
service calls is given in axml.xsd. For example,
a simple active document looks like this:
BEFORE:
<example xmlns:axml="http://futurs.inria.fr/gemo/axml/">
<axml:sc axml:id="version">
<axml:return>
<axml:append />
</axml:return>
<axml:ws-soap endpoint="http://localhost:6969/MyPeer/services/Version">
<v:getVersion xmlns:v="unknown" />
</axml:ws-soap>
</axml:sc>
</example>
As shown in the example, service call is an element in a special namespace and it has the following features:
- id that, formally speaking, represents current nodeID
(current peerID and current docID are the peer and document where this example lies
in the repository) of the service call node. The id must be unique within the document, therefore incoming data may require fixing to conform
to this requirement
- return statement that specifies what to do with results. In the example it is shown that the results should be
appended. One can also specify other things, e.g., for how long the results are valid.
- the specification of how to reach the Web service. In the example it is shown that it will be called using a SOAP message with
the provided payload (the root normally corresponds to the operation name). Besides one can call a Web service REST style, which roughly corresponds
to submitting an XForm via GET or POST. Note that the payload can contain active data!
Beside the listed features service call can be setup to execute after other service call(s). It is also possible to
impose periodical execution, however, this is not advised, because this feature still needs much thinking and may later be removed because
it is very expensive.
AFTER:
<example xmlns:axml="http://futurs.inria.fr/gemo/axml/">
<axml:sc axml:id="version" activated="2007-10-22T19:17:33.921+02:00">
<axml:activation status="TERMINATED"/>
<axml:return>
<axml:append/>
</axml:return>
<axml:ws-soap endpoint="http://localhost:6969/MyPeer/services/Version">
<v:getVersion xmlns:v="unknown"/>
</axml:ws-soap>
</axml:sc>
<ns:return xmlns:ns="http://axisversion.sample" axml:origin="version" axml:timestamp="2007-10-22T19:17:35.484+02:00">
Hello I am Axis2 version service , My version is 1.3
</ns:return>
</example>
After materializing the service call in the example the document changed in the following way:
- a result arrived. It was marked with the origin and timestamp. Note that the
origin refers to the id of service call and this reference should not be broken when data is traveling around the network.
- the service call was marked as TERMINATED and was assigned the activation timestamp
For information on where to put a document, how to activate a service call, evaluate the whole document, etc. please see the demo.
Worth mentioning that it is done by calling peer's Web services.
Internals of Service Call Materialization[TODO]
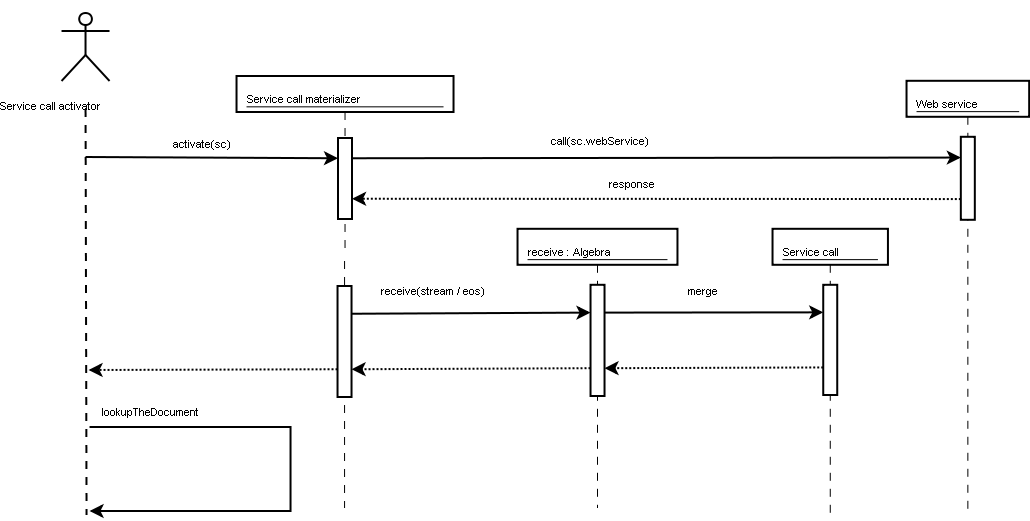
Demo [TODO]
Interface of a Peer [TODO]
Back to top
Developer Guide
Developers that want to dive into the code and better understand the architecture of
ActiveXML should find useful information here. Before going into details it
is worth mentioning that it would be a good
idea to transform the project into a Maven2 project which would easen the way
dependencies are downloaded and the project is built.
Organization of Sources
The project is developed using Eclipse, therefore it is to start contributing to the code
one needs to checkout the whole project from the CVS(or SVN) repository and configure the used libraries. Currently (2007-11-27)
the new version of ActiveXML is branched (almost forked) into the branch 'eXist' and also tagged as 'V2'.
In other words to get the latest changes use the branch 'eXist' and to get the last working version use the tag 'V2'.
ActiveXML depends on the following libraries:
- AXIS2 - contains all the .jar files from axis2.war/WEB-INF/lib/. As it was mentioned ActiveXML
is using Axis2 internally to realize the server side
- EXIST - contains three .jar files (exist.jar, xmldb.jar, xmlrpc-1.2-patched.jar).
These contain the classes needed to implement a driver for the active documents repository using eXist XML database
- GWT - contains gwt-dev-windows.jar (for Windows), gwt-user.jar. These libraries are used for
creating AJAX Web application (servlets and GUI) using Google Web Toolkit. It is of course optional to do it this way, and the dependency is not very tight.
- OPTIMAX - optimax.jar. Actually the dependency should be other way, i.e. Optimax should depend
on ActiveXML because it is a plug-in. However, since it was developed in a hurry now Optimax is
split into two parts, this should be fixed the sooner the better
When the code is downloaded, libraries are configured and finally the project compiles in Eclipse without errors it is fine to analyse the sources deeper.
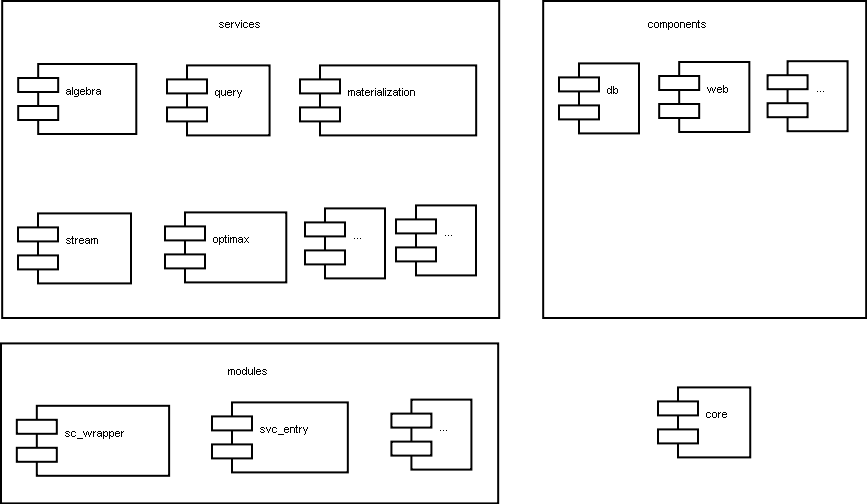
The code (end the whole software) can be divided into the following parts:
- core - it is the implementation of the ActiveXML engine. It does not (and should not) depend on other parts.
Although it is not a lot of code still it is very painful to change it.
- src contains all the interfaces that represent the general concepts of ActiveXML, such as
a service call, materialization, merge function, result, etc. This is the most sensitive area because here the interfaces are defined. Changing an interface
means possibly breaking the contract causing compatibility issues.
- impl is an implementation of what's inside src. The most important aspect of the implementation
is a heavy usage of XQuery: in order to avoid loading all the documents into memory tiny skeleton objects are created; when
data is needed a query is posted to the repository. This might become a bottleneck at some point due to excessive querying and parsing,
therefore some careful investigation is needed.
- peer realizes the concept of a peer that has documents and services
- jaxb contains the generated code with some meta information. The code is generated out of
ActiveXML related .xsd files using ActiveXML/binding.xml (it is an Ant file with tasks).
-
components - these are loosly coupled components that could have different implementations.
- components/web component is the Web application that helps to interact with the peer, in other words this is
a GUI
- components/db component contains the DB access API and eXist driver
- services - are the ActiveXML Web services (plug-ins). They are deployed into
Axis2 repository
- modules - are the collections of handlers (in Axis2 terms)
- modules/sc_wrapper is responsible for dealing with the outgoing message when a service call is activated.
Currently the main purpose of it is to enrich the SOAP message with information headers about which service call is being called
- modules/svc_entry deals with an incoming message. Its main purpose is to initialize the ActiveXML context
so that plug-ins (Web services) are able to reach information about documents and services available on the peer
Every listed item have associated build.xml in a respective folder. There are separate output folders (where the .class files go)
for every component, service, module, and the core. So development goes like this:
- Decide where the source should go. In most of the cases a new component or a service will need to be developed
- Create a folder in respective place and make it as source (Eclipse: [right click]->Build Path...->Use as Source Folder)
- Configure the output folder for the new sources (Eclipse: [right click]->Build Path...->Configure Output Folder). Normally it should be
a bin folder inside
- Update the respective build.xml to get a .jar, .aar or .mar out of the sources (see how to build)
Inside ActiveXML/resources there are all the .xsd files that define syntax for different things. The schemas
are quite documented so they will not be covered here:
- axml.xsd defines syntax for service calls
- axml_related.xsd defines some types that are used by the core of the engine. For instance communication headers for SOAP messages
- algebra.xsd defines syntax of SEND, RECEIVE, NEWNODE algebra services
- materialization.xsd defines syntax for materialization services, e.g. activation of a service call, evaluation of a document
- query.xsd defines syntax for query services, e.g. generic query, declarative query
Since the most difficult is axml.xsd it is advisable to use this schema when creating active documents from the scratch.
For instance, Eclipse shows the autocomplete and documentation for elements and types when the the .xsd is included using xsi:schemaLocation attribute. Any other
XML editing tool should also provide that.
Building and Creating a Distribution
When everything compiles in Eclipse still specific build procedure must be held in order to properly deploy ActiveXML.
To understand the building process it is enough to go through all the build.xml files in the project. Before doing any
builds or bindings ActiveXML/build.properties must be updated. Bellow the comments on build files is given:
- ActiveXML/build.xml used for building everything into .jar, .aar, .mar and web components. By default
the resulting resources are put under ActiveXML/build/. This build file is
actually calling targets from several other build files:
- ActiveXML/services/build.xml used for creating Axis archives of the services that are being developed
- ActiveXML/modules/build.xml used for creating Axis module archives of the modules
(collections of handlers) that are being developed
- ActiveXML/components/build.xml used for building other independent components. Moreover this build file
creates actual peer webapps. It puts all the .jar, .aar, .mar files into right places of a webapp and this is how
MyPeer is born
- ActiveXML/distribution/build.xml used for creating the whole distribution that can be zipped and shipped for
the end users. It transforms Tomcat into ActiveXML distribution by including certain built resources
from ActiveXML/build/ and eXist into right places (see
installation and configuration for details)
Back to top
Development scripts[TODO]
For development use ant file buildDev.xml and buildDev.properties.
Back to top
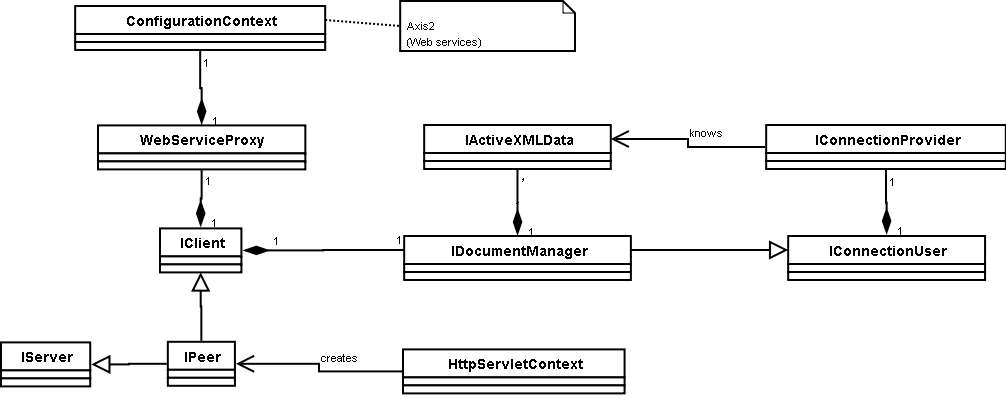
Static Architecture [TODO]

 Back to top
Back to top
Functionality of ActiveXML
An active xml document contains service calls. They could be calls to any web service or to specific ActiveXML web services
(MaterializationService,
OptimaxService, GenericQueryService, DummyStreamService, algebra service: ReceiveOperator, SendOperator, NewNodeOperator).
We would like to explain in this section the functionality of each web service, and the chain of execution from when a service call is activated
until the results are received and appended to the active document.
We identify two parties:
- Client: It contains an active axml document with service calls. It represents the place where a service call(sc)
is materialized (the corresponding web service is called) and where the results are collected and saved into the document.
- Server: The place where service calls are executed;
AXML syntax
It explains the syntax of xml schema files (.xsd) described in section Organization of sources
axml.xsd
The activation status of a service call has multiple possible value:
- ENABLED is always set by default, when you don't specify anything it is there.
- ACTIVATED:
- FAILED is set when the service call execution fails, for instance, when the materializer catches an exception while calling the Web service.
- DISABLED is used to disable a service call !!!! TODO
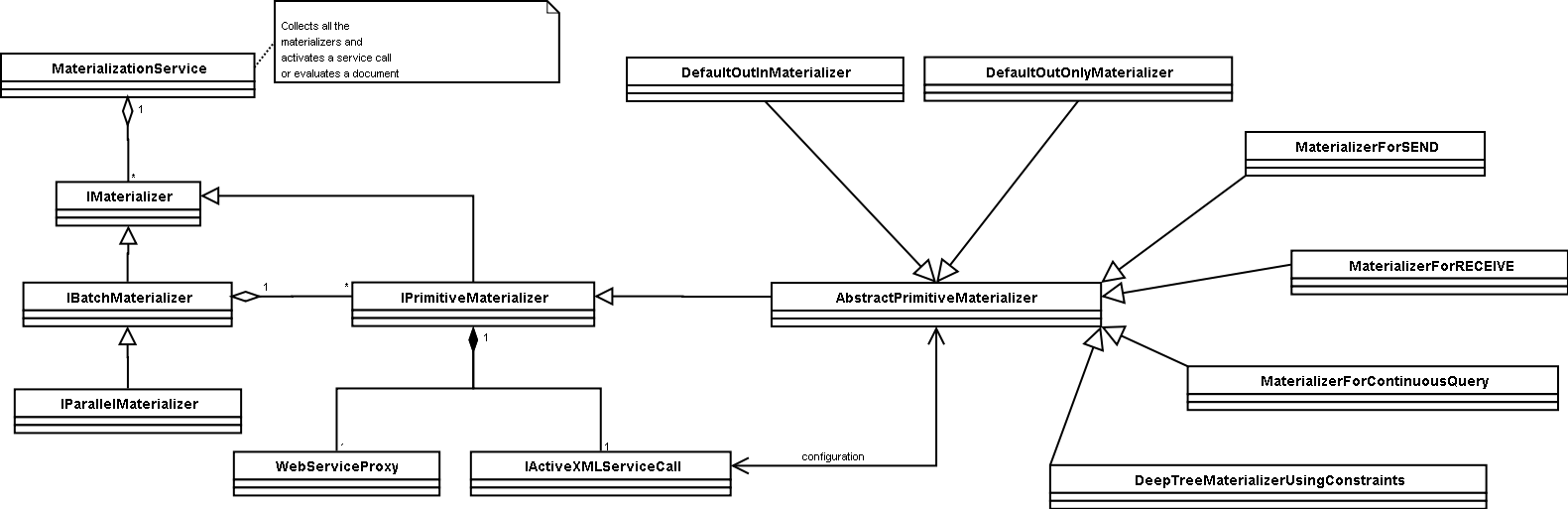
Materializers' description
A service call is materialized (call Web service, consume result) by materializers.
A service call (sc) one can set the materializer class. This class is instantiated when creating a service call object.
All the materializer related classes are in fr.inria.gemo.axml.model.sc.materialization:
-
DefaultOutOnlyMaterializer is used for simple service calls that do not have <return>, or have <return><void></return>
-
DefaultOutInMaterializer is used for simple service calls that have merge function specified inside <return>.
-
MaterializerForRECEIVE is assigned for sc that are RECEIVE. This materializer does not call any Web service but
simply makes the service call active
-
MaterializerForSEND is assigned to SEND service calls. According to SEND semantics it sends everything underneath it until the end of stream.
This means, that it is listening to the service calls bellow it and on new result it this materializer calls respective RECEIVE Web service.
-
MaterializerForContinuousQuery behaves similarly to SEND, i.e. it is watching the service calls underneath it,
but instead of calling a RECEIVE on the server, it calls the respective GenericQueryService.
MaterializerUsingConstraints and DeepTreeMaterializerUsingConstraints is a helper for
MaterializationService. These materializers are not designed for service calls.
Q: What happens if the materializer is not specified in the activexml document?
There is a IMaterializer interface which has one method: materialize().
There is a class implementing this interface which is able to deal with
a batch of materializers, i.e. given a batch of IMaterializer instances
it calls in parallel their materialize() method, it returns when all the
threads join. This way you can combine simple and batched materializers
to have any order of materialization.
There is also another flavor of batch materializers: materializer with
constraints. It keeps a buffer of materializers which constrain its
execution with afterActivated and afterTerminated, so every time
something is activated or terminated it tries to execute or waits till
the constraints are satisfied.
The materializers with constraints are used by MaterializationService.
When you want to evaluate a document such a materializer is created by
collecting the afterActivated and afterTerminated constraints, then
materialize() is called and all the service calls are
materialized with the given constraints.
So to materialize service calls you simply create materializer objects
for them. The materializers can extend functionality of a service call,
as it is with SEND and RECEIVE (therefore you need to specify the
special materializers for them), but in general there is a default
materializer which looks at the service call, creates the SOAP message,
calls the Web service and deals with the result.
Back to top
ActiveXML Web services' implementation
GenericQueryService
Back to top
Activation: Chain of execution
Creating a Plug-In Web Service [TODO]
How to Develop Without Interfering With the Existing Code
ActiveXML currently requires two kinds of development: 1) debugging or optimization
and 2) plug-ins or applications. The former kind implies changes in the current code, however, one should perfectly know what she's doing.
The latter is the final goal of how code should be contributed to ActiveXML. Good systems are always pluggable platforms
and ActiveXML must become one of those because of its SOA nature.
As it was mentioned earlier plug-ins in ActiveXML correspond to Web services. Every Web service can utilize the internals
of the ActiveXML (activation of service calls) and bring new functionality. For example,
Optimax is heavily using the engine for optimizing active documents in a distributed environment (please refer
to Optimax documentation for details). Another example, could be a catalog service that would crawl the distributed
network and catalog all the Web services that it finds.
It is a good place here to remind that ActiveXML also is extensible on a service call level. Axis2
allows to plug modules that would intercept a traveling SOAP message. This is one way of decorating the behavior of a Web service (and therefore a
service call). On the other hand it is not always appropriate to use Axis2 handlers because the
chain of execution design pattern is not always suitable which is the case, for instance, in algebra services.
Therefore it is possible to attach a specific implementation of the AbstractPrimitiveMaterializer that would capture the logic
of materialization of a service call. For instance, MaterializerForSEND, MaterializerForReceive,
MaterializerForContinuousQuery use this feature.